In modern TV production, effective communication is crucial. Legacy intercom systems have often been complex, costly, and proprietary, limiting flexibility and scalability. The Open Source Intercom Solution, developed in cooperation with major Nordic broadcasters, leverages WebRTC technology to provide a modern, scalable, and easy-to-use alternative.
This guide will walk you through setting up and using the latest release of the Open Source Intercom Solution, ensuring seamless communication in your production environment. Whether you’re a seasoned broadcast professional or new to live production, this guide provides all the details you need to deploy and operate the system efficiently.
Key Features of the New Release
The latest update brings significant improvements, ensuring a more streamlined and user-friendly experience.
Some of the key enhancements include:
• A completely reworked and improved user interface, designed to be more intuitive and easier to navigate.
• Support for multiple calls in one browser window, enabling users to manage multiple communication lines more efficiently without switching between windows.
• Device switching during a call, allowing seamless transitions between different audio input and output devices.
• Volume control visibility on supported devices, ensuring that users can adjust audio levels more precisely.
• New participant muting functionality, allowing users to mute other participants when necessary to maintain clear communication.
• Audio functionality, where program output audio is automatically lowered when another participant speaks on a different line, enhancing clarity in live production settings.
• Numerous bug fixes and general performance improvements, ensuring a smoother, more reliable experience.
These features collectively enhance usability, making the intercom solution a powerful tool for broadcast communication.
Prerequisites
Before getting started, ensure you have the following in place:
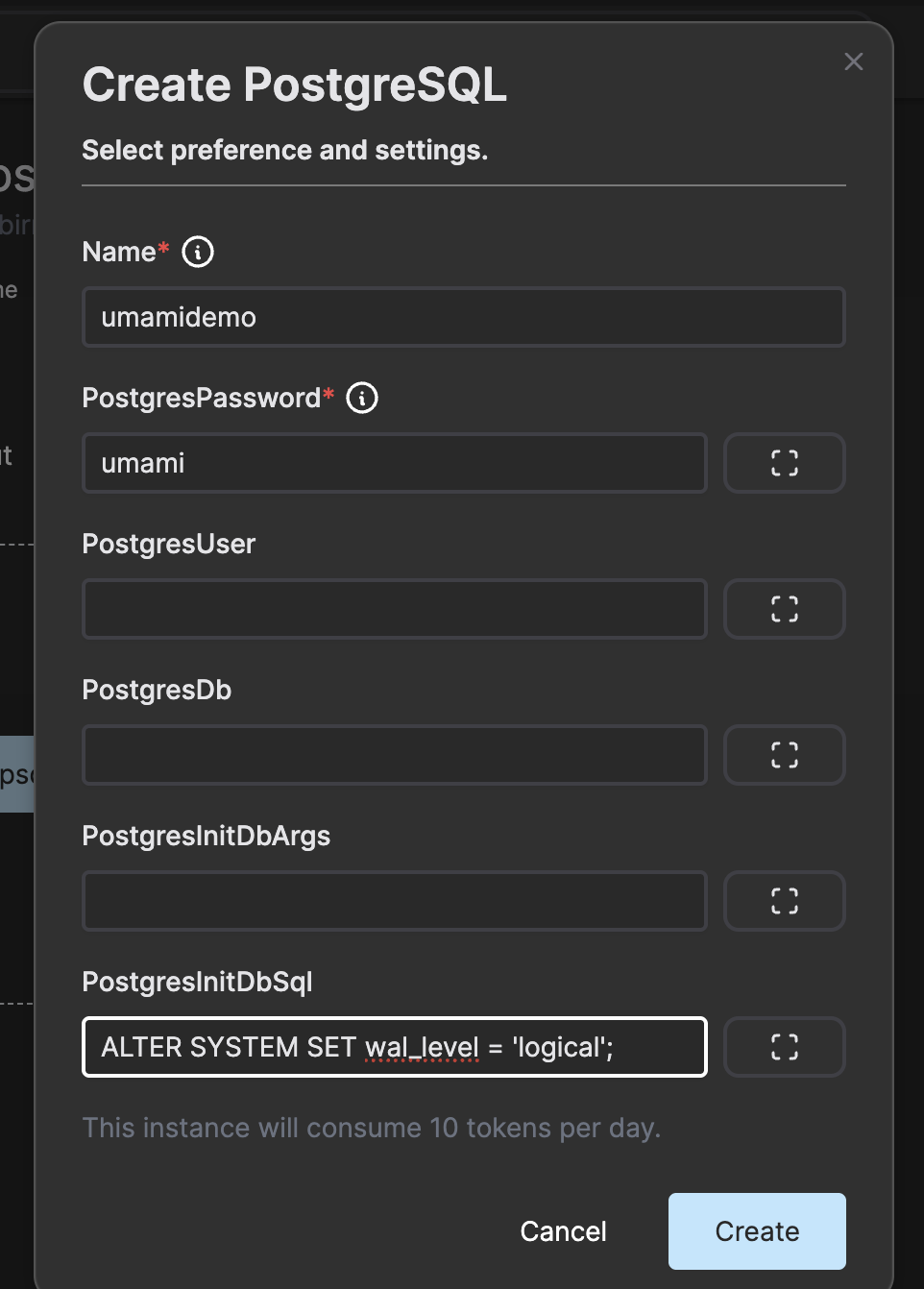
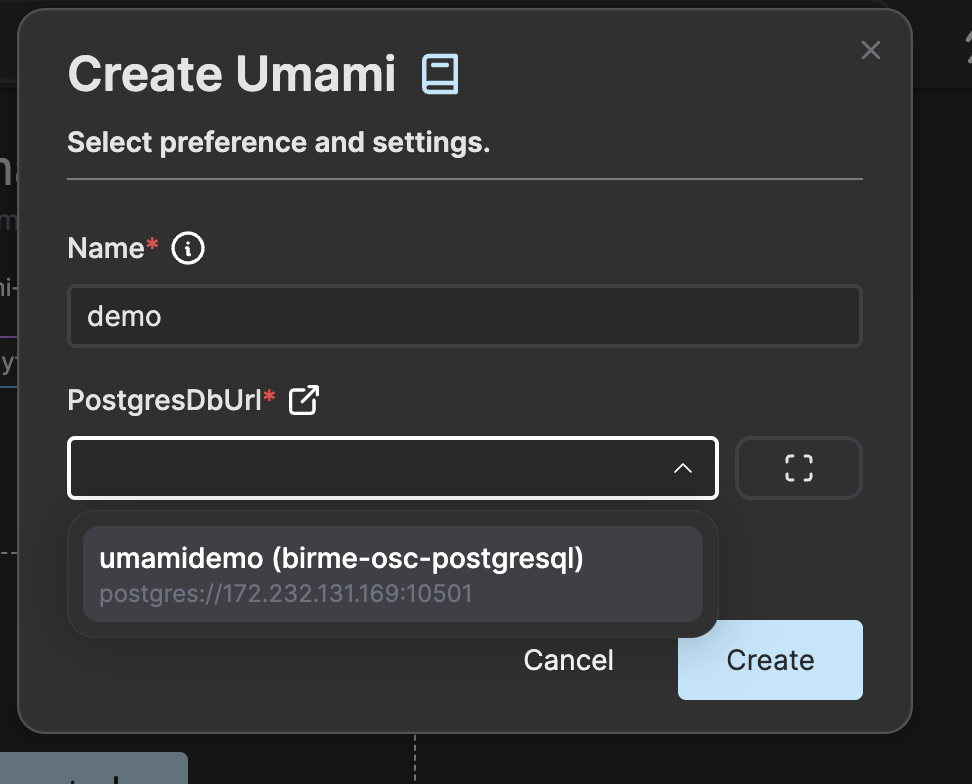
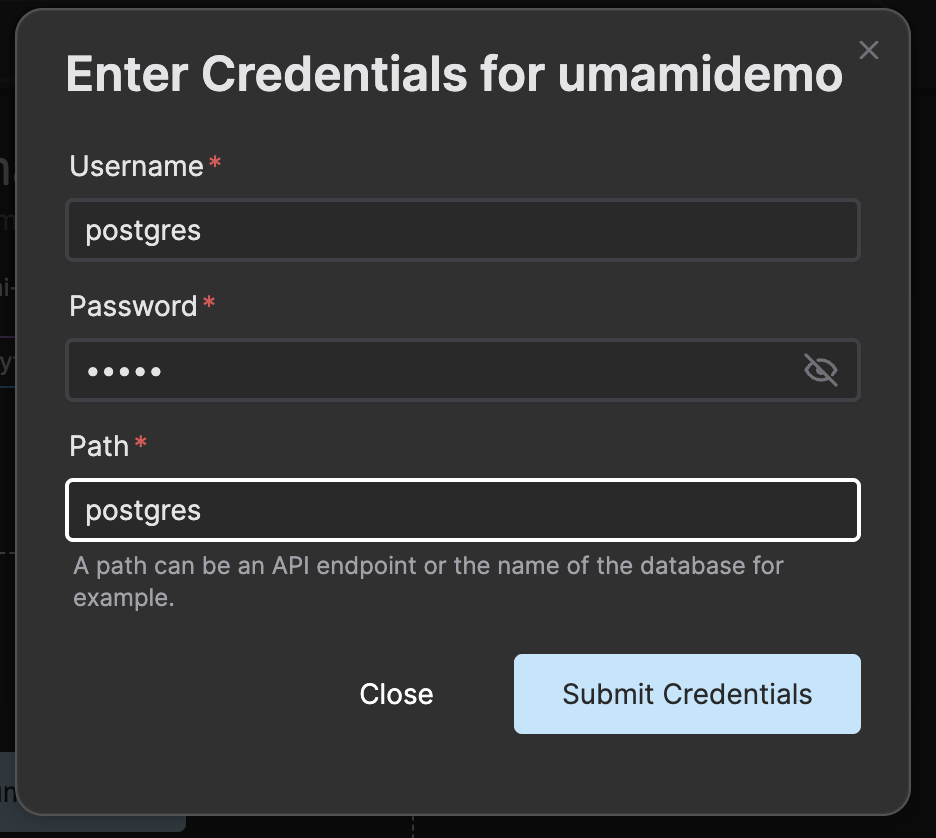
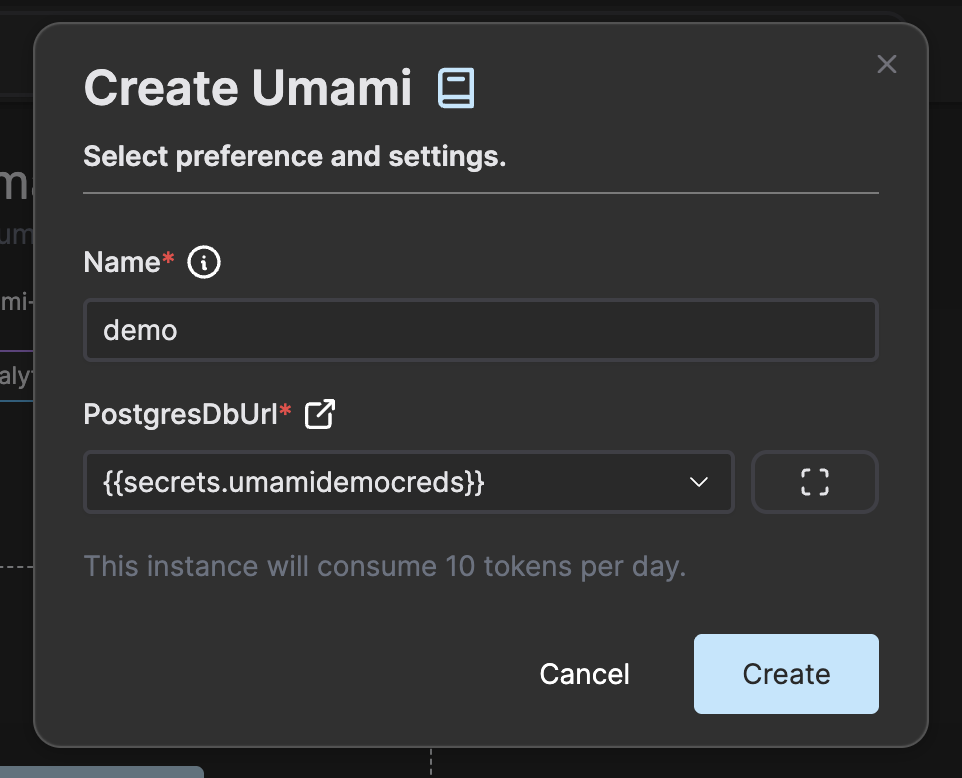
• An Open Source Cloud account (https://app.osaas.io/), which provides access to the hosted intercom service.
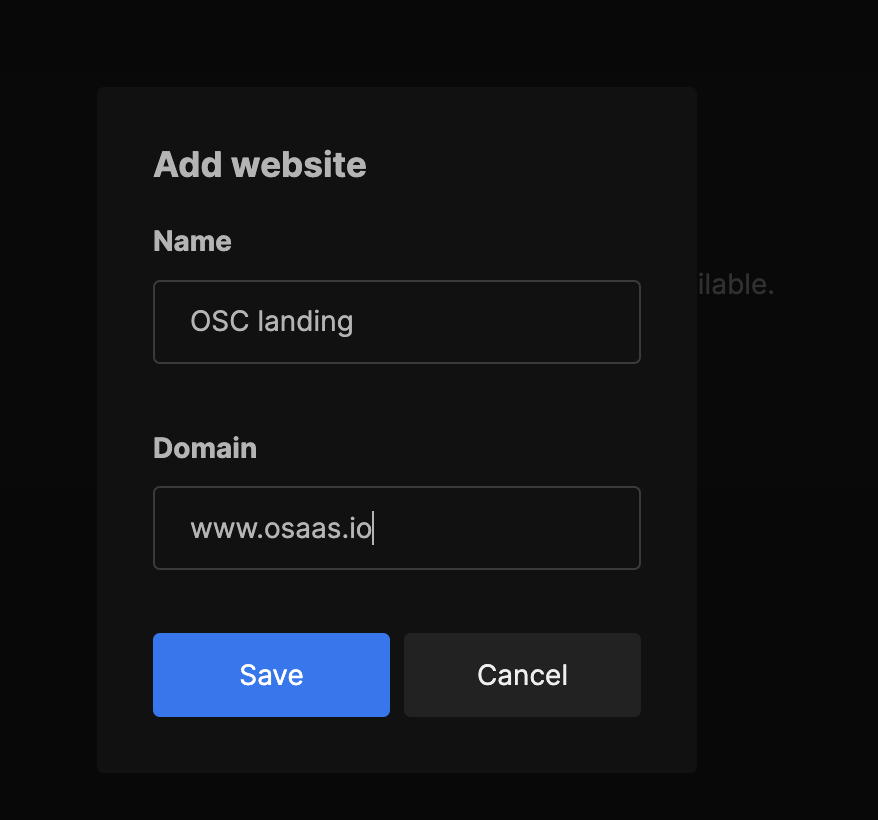
• An Intercom service instance created, enabling communication channels to be established.
If you don’t have an account yet, signing up on https://app.osaas.io/ is quick and simple.
Logging In & Opening the Intercom App
To begin using the Open Source Intercom Solution, follow these steps:
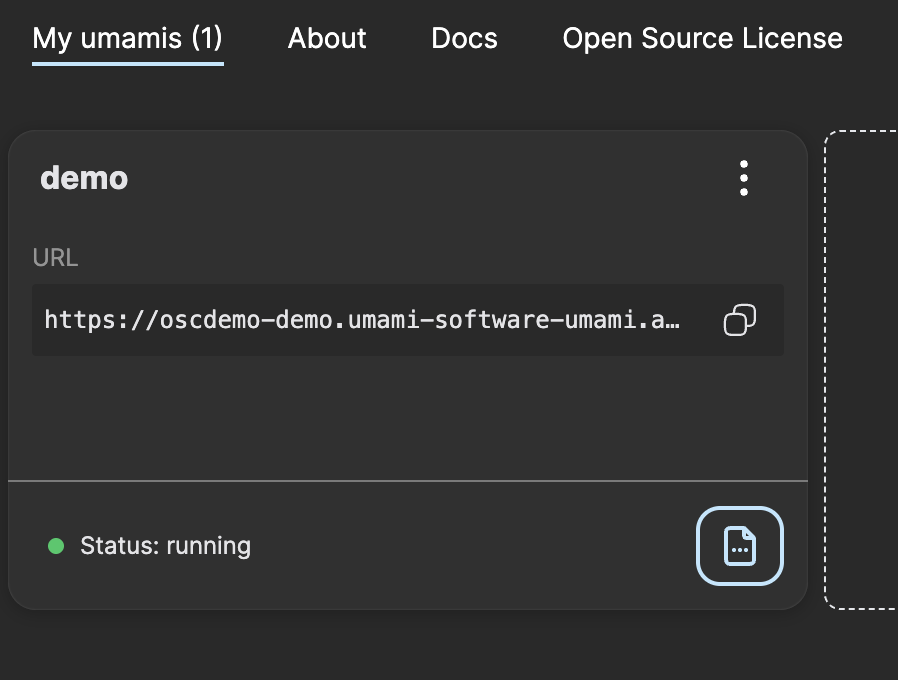
• Log into https://app.osaas.io/.
• Navigate to the Intercom service in your dashboard.
• Click the three dots next to your running service and select Open Application to launch the intercom interface.
Once opened, the system is ready for production setup and communication.
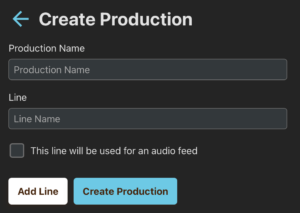
Setting Up a Production
To configure a new production, follow these steps:
• In the Create Production section, enter a Production Name.
• Specify a Line Name (both fields are mandatory for creating a new production).
• If required, click Add Line to include multiple communication lines for different teams.
• Click Create Production to generate a unique Production ID.
Your new production will now be added to the list of recent productions.
To share the production with others, join the production and copy the URL from your browser’s address bar.
Joining a Production
Once a production is set up, users can join by following these steps:
• In the Join Production section, enter your Production ID and your Name.
• Choose the appropriate Microphone and Speaker settings.
• If your desired device does not appear, refresh the browser page.
• iPhone users may need to reload the page to detect the correct microphone and speaker.
• Select the Production Line you wish to join and click Join.
After joining, you will have full access to the intercom communication features.
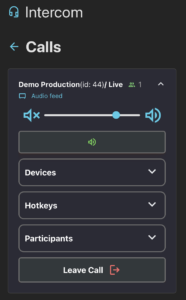
Using the Intercom System
Once inside the system, users can leverage the following controls:
• Mute/unmute audio, allowing participants to manage their audio input effectively.
• Mute/unmute microphone, giving users control over their speaking permissions.
• Push-to-Talk (PTT) button, which activates the microphone only while pressed, ensuring clear and concise communication.
• Hotkeys support, allowing integration with external hardware like StreamDeck for more streamlined operations.
These features ensure a seamless and efficient communication experience for production teams.
Why Choose the Open Source Intercom Solution?
A Flexible, Open-Source Alternative to Proprietary Systems
Traditional intercom systems often come with high costs, proprietary limitations, and complex infrastructure requirements. The Open Source Intercom Solution eliminates these barriers, offering a more affordable, adaptable, and high-performance alternative.
Designed for Simplicity & Scalability
• Easy deployment: The system is available as a containerized package, meaning it can be deployed on standard IT infrastructure or hosted remotely in the cloud.
• Compatible with any retail hardware, so you’re not tied to a specific vendor’s equipment.
• Quick setup, enabling users to configure productions in a matter of seconds.
• High-fidelity audio powered by the Opus codec, ensuring professional-grade sound quality.
Powered by WebRTC for Real-Time Communication
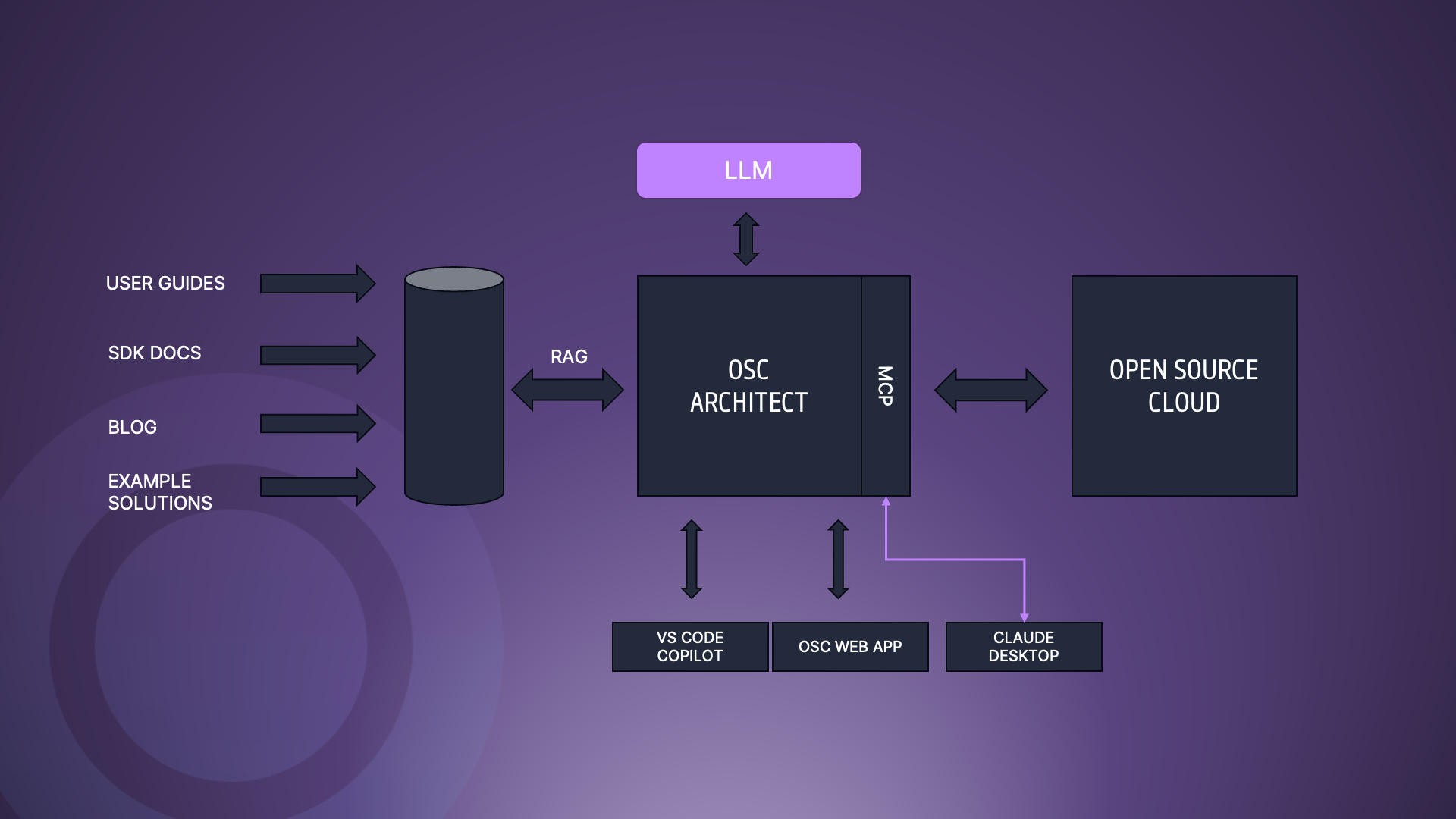
The system leverages WebRTC technology, which is widely adopted for real-time communication applications, offering low latency and cross-platform support. The architecture consists of:
• Symphony Media Bridge (SMB) – The core Selective Forwarding Unit (SFU) that routes media streams efficiently between participants.
• Intercom Manager – Handles backend communication control and session management.
• Intercom Frontend Manager – Provides an intuitive, web-based user interface
By using modern, web-based technologies, this solution ensures reliable performance, ease of use, and broad compatibility with existing workflows.
Conclusion
The Open Source Intercom Solution is a forward-thinking approach to broadcast communication. With its user-friendly design, open-source flexibility, and superior audio performance, it offers a scalable and cost-effective alternative to traditional intercom systems. Whether you’re a broadcaster looking to modernize your communication infrastructure or a production team in need of an intuitive and efficient intercom system, this solution provides a seamless way to stay connected.
Get started today by logging in to https://app.osaas.io/ and exploring the possibilities of modern, open-source intercom technology!